Здравствуйте. Сегодня я расскажу о том, как с помощью программы Abbyy FineReader распознать текст c изображения, которое вы могли получить в результате сканирования. Ваш сканированный текст будет полностью в документе Microsoft Word и этот распознанный текст можно будет редактировать! Распознать текст при помощи Abbyy Finereader может пригодиться тем, кто учится, работает с текстами и переводами. Программа, к сожалению, является платной. Как-то доводилось попробовать одну из бесплатных вариантов аналогичных программ, но весьма хорошо отсканированный текст распознается просто ужасно... А распознать текст в Abbyy FineReader получается весьма качественно! Сейчас я покажу как пользоваться программой Abbyy FineReader для быстрого распознавания текста с изображения.
ABBYY FineReader имеет пробную версию на 30 дней с возможностью распознавания до 100 страниц и сохранением не более 3-х страниц из документа. Т.е. в течение этого времени вы можете увидеть возможности программы и принять взвешенное решение — нужна ли она вам, стоит ли её покупать или нет.
Перед тем как пользоваться Abbyy Finereader её необходимо установить. Рассмотрим процесс установки этой программы...
Для начала выбираем язык программы. Нажимаем «ОК».
Принимаем условия лицензионного соглашения (при желании можно прочесть лицензионный договор, если вам интересно о чём там речь). Нажимаем «Далее».
Далее вы должны выбрать режим установки. При обычном режиме программа не спросит вас и установит то, что в программе задано по умолчанию, а именно — все компоненты: саму программу Abbyy Finereader для распознавания текста, компонент для программ Microsoft Office и компонент для проводника Windows (позволяющий быстро распознавать изображения, не открывая отдельно программу). Советую отметить выборочную установку чтобы настроить так, как вам нужно. Тем более это не займет и 15 минут:) Внизу указана папка куда установится программа. Желательно оставить выбор по умолчанию, чтобы потом не было никаких проблем при использовании программы. Нажимаем «Далее».
Компоненты программы. Это окно как раз появится в случае, если вы выберите тип установки «Выборочная». Компоненты — это что-то вроде вспомогательных приложений к программе. Первый компонент «Интеграция с программами Microsoft Office и Проводником Windows». Этот компонент будет отображен в меню Microsoft Office и если вы щелкните по изображению у себя на компьютере правой кнопкой мыши, то там будет пункт с этой программой. Вот так будет выглядеть ваше меню в Microsoft Office после добавления этого компонента.
А вот что будет если вы щелкните правой кнопкой мыши по изображению:
Т.е. появится меню, в котором вы можете сделать быстрое распознавание текста с отправкой результатов в Word, Excel или PDF.
Второй компонент позволит вам распознать текст с экрана компьютера. Это значит, что вы сможете сделать скриншот и также распознать текст. Если вы не хотите устанавливать один из этих компонентов, или вовсе не хотите устанавливать оба, то нужно нажать на стрелочку вниз и выбрать «Данный компонент будет недоступен». Тогда компонент установлен не будет. Я оставила оба.
Далее 4 пункта. 1-ый означает то, что сведения о том, как вы пользуетесь программой Abbyy Finereader будут переданы разработчику. Данный пункт советую не отмечать, чтобы программа лишний раз не выходила в интернет ради отправки сведений о работе с ней. Тем более, мало ли какие ещё сведения будут отправляться:) 2-ой пункт создает ярлык программы на рабочем столе. 3-ий означает, что программа будет запускаться при включении компьютера, а 4-ый будет проверять обновления программы. Я оставляю только второй и напротив него оставляю галочку. Закрываем все приложения Microsoft Office, потому что так требует установщик и нажимаем «Установить».
Нужно подождать пару минут чтобы программа загрузилась и нажать «Далее».
Все, установка завершена! Нажимаем «Готово».
Рассмотрим, как пользоваться программой. К примеру, у вас есть отсканированный текст. Теперь, чтобы распознать текст в Abbyy FineReader, открываем программу. Нажимаем «Открыть».
Выбираем нужное нам изображение и нажимаем открыть.
Когда вы откроете нужный документ, Abbyy Finereader начнёт распознавать текст. Чем больше документ, тем дольше будет длиться распознавание. Распознавание одной страницы может занять несколько секунд.
После того как текст распознается вам останется только сохранить результат в документ Microsoft Word, чтобы затем вы могли отредактировать в нём что угодно. Для этого нажмите кнопку «Сохранить» на верхней панели инструментов, после чего выберите в какую папку будет сохранён документ Word и под каким названием.
Если у вас подключён к компьютеру сканер, то вы можете запустить сканирование прямо из программы, и после чего отсканированный документ сразу будет распознаваться. Для этого на верхней панели инструментов нажмите кнопку «Сканировать». Далее действия будут зависеть от программы-драйвера для вашего принтера. Вам нужно только следовать указаниям мастера сканирования.
Как видите, все очень просто и быстро. Теперь вы знаете, как пользоваться Abbyy FineReader для распознавания текста с изображений! Надеюсь, что эта информация очень поможет многим:) Удачи!
История Abbyy FineReader насчитывает уже более 20 лет. Юбилейный 2013 г. компания отметила выпуском полновесного (по сравнению с Express Edition от 2009 г.) Abbyy FineReader Pro для Mac, а через пару месяцев, в феврале 2014 г., свой «подарок» получили и пользователи Windows - Abbyy FineReader 12 Professional и Corporate. Напомню, что предыдущая версия появилась еще в 2011 г. , а два с половиной года срок немалый - давайте разбираться, насколько существенны изменения.
Системные требования для новой версии совершенно не изменились. Платформой может служить Windows или Windows Server начиная от XP и 2003 соответственно. Аппаратные запросы по нынешним временам и подавно скромны: процессор любой разрядности с частотой от 1 ГГц, оперативной памяти не менее 1 ГБ плюс по 512 МБ на каждое вычислительное ядро и т. п. Несколько увеличилась только потребность в дисковом пространстве - теперь для установки требуется не 700, а 850 МБ (плюс, по-прежнему, еще 700 МБ для рабочих файлов).
Естественно, речь идет о минимальных требованиях; полностью возможности Abbyy FineReader 12 Professional раскроются только на сравнительно современных системах. В частности, напомню, что программа умеет эффективно распараллеливать обработку отдельных страниц, задействует при этом все процессорные ядра и загружает любой процессор почти на 100%. А вот к оперативной памяти она действительно не жадная, и даже остается 32-разрядной.
Не претерпела изменений и процедура установки: минимум вопросов и опций. В комплекте с Abbyy FineReader 12 Professional по-прежнему идет Abbyy Screenshot Reader, который становится работоспособным только после регистрации пользователя.

После этого также откроется доступ к техподдержке.

Даже на основе этой скромной информации можно предположить, что перед нами результат эволюции. Соответственно, в дальнейшем я сосредоточусь на описании изменений по сравнению с предыдущей версией, которые условно можно разделить на две основные группы: работа с программой (интерфейс, вспомогательные инструменты, удобство использования) и OCR (качество и производительность собственно распознавания).
Abbyy FineReader 12 Professional демонстрирует некоторые доработки в части пользовательского интерфейса. Это сразу же заметно на окне Задачи, которое по умолчанию открывается при запуске программы. Оно, очевидно, имитирует концепцию плиток Windows 8.x и адаптировано для управления пальцами, тем более, что в программе также поддерживаются и основные жесты вроде прокрутки и масштабирования. На деле же, изменения коснулись только «фасада», да и то отчасти - рядом с плитками соседствуют обычные элементы управления и в процессе настройки любого сценария придется иметь дело со стандартными диалоговыми окнами. Работать с ними пальцами довольно проблематично, особенно на экранах 8-10″, которые становятся популярными у Windows-планшетов.

Представить же, что пользователь такого планшета, оснащенного камерой, может захотеть быстро «на ходу» ввести какой-то печатный документ, действительно несложно. Между тем вся история Windows, начиная с первой редакции Tablet PC, подтверждает бессмысленность адаптации к сенсорному управлению стандартного настольного интерфейса. По-видимому, для этих целей гораздо правильнее создавать специальную оболочку, соответствующую всем канонам Metro, но использующую тот же «движок». Примером подобного решения служит Internet Explorer из Windows 8.x. К тому же, у Abbyy даже имеется некий задел в виде Abbyy FineReader Touch для Windows 8, который использует облачный сервис компании.
Если же отвлечься от сенсорного ввода, то найдутся еще изменения данного класса - от вполне ожидаемого обновления окон открытия/сохранения документов, которые, среди прочего, обеспечивают простой доступ к облачным хранилищам (при наличии в системе соответствующего агента и его папки), до нескольких более важных и полезных.

Обработка страниц в Abbyy FineReader 12 Professional теперь выполняется в фоновом режиме. Это подразумевает отсутствие прежнего модального окна со статусом операций (теперь данную роль играет строка статуса внизу экрана) и, соответственно, наличие доступа к интерфейсу. Таким образом пользователь имеет возможность работать с программой параллельно процессу распознавания (если он, конечно достаточно длительный), к примеру, копировать фрагменты полученного текста или даже корректировать разметку страниц - последние при этом будут поставлены в очередь и обработаны заново.

В отличие от прежней версии, также не происходит перелистывания страниц по мере распознавания или при начальной загрузке документа, если автоматическое распознавание отключено. В Abbyy FineReader 12 Professional документ загружается и разбивается на страницы практически мгновенно, а их эскизы строятся только по мере ручного пролистывания в левой панели. Кроме всего прочего, тем самым экономятся вычислительные ресурсы, причем, довольно ощутимо на больших многостраничных документах.
Остальные изменения данного класса не столь интересны, хотя и могут пригодиться в каких-то сценариях, поэтому о них кратко.
Если нужно не обработать документ целиком, а лишь процитировать отдельные места, то можно отключить все автоматические операции и выбирать необходимые фрагменты любых типов, сразу же копируя их в буфер обмена - при этом анализ и распознавание будут выполняться на лету.


Для получения результата с более простой структурой, чем у оригинала, можно отключать воссоздание колонтитулов, сносок и других элементов макета. Это может пригодиться, к примеру, при подготовке электронных книг.

Продолжая об электронных книгах - в Abbyy FineReader 12 Professional поддерживаются форматы EPUB 2.0.1 и 3.0.

Расширены параметры преобразования в XLSX, к примеру, появилась возможность очищать форматирование или сохранять картинки.

При сохранении результирующих документов в PDF с текстовым слоем теперь можно воспользоваться новой технологией Abbyy Precise Scan, которая заключается в сглаживании символов на оригинальных изображениях страниц. Доступна она, кстати, только в цветном режиме.

Эффект от ее работы достаточно заметен, хотя и не всегда, скажем так, «академичен». Впрочем, читабельность сглаженных символов в любом случае должна быть выше, а в данном примере оригинал действительно очень низкого качества.


Теперь давайте разберемся, какие улучшения произошли в механизмах собственно распознавания.
Разработчики сообщают об очередном этапе совершенствования технологии ADRT, которая, напомню , анализирует и воссоздает логическую структуру документа. Декларируется, что она стала работать гораздо точнее, особенно с таблицами, списками, диаграммами. Продемонстрировать это адекватными примерами не так просто, но не невозможно. Вот, к примеру, результаты распознавания (с настройками по умолчанию) одной и той же страницы в Abbyy FineReader 11 Professional (вверху) и Abbyy FineReader 12 Professional (внизу).


Старая версия выделила и обработала только основной текстовый блок, возможно, из-за низкого качества оригинала сочтя остальные элементы «мусором». Новая, напротив, корректно опознала список и попыталась его воссоздать. Результат, правда, не идеален: то что распознаны не все маркеры можно, опять же, отнести на качество изображения, но программа, по-видимому, все же не поняла, что перед ней содержание, иначе не интерпретировала бы цифры как буквы. Тем не менее, прогресс налицо и на более качественных оригиналах подобных претензий, возможно, не было бы.
А вот как обрабатывается «неявная» таблица без разделительных линий - Abbyy FineReader 11 Professional (вверху) и Abbyy FineReader 12 Professional (внизу).


Хорошо видно, что старая версия, в отличие от новой, вообще не увидела здесь табличной структуры и ограничилась набором несвязанных между собой текстовых блоков. Не поленитесь щелкнуть на изображениях и сравнить результаты распознавания - у Abbyy FineReader 12 Professional он близок к идеалу.
К сожалению, так происходит не всегда и уже на соседних страницах Abbyy FineReader 12 Professional показал результаты, аналогичные Abbyy FineReader 11 Professional. Хотя именно ADRT должна была бы отследить одинаковые «шапки» и понять, что перед ней своеобразная перетекающая таблица.

Но все равно хорошо заметно, что обновленные алгоритмы обращают внимание на большее количество деталей чем ранее. В процессе тестирования Abbyy FineReader 12 Professional наблюдалась, к примеру, даже попытка интерпретировать как таблицу картинку с упорядоченным размещением на нем текстовой информации. Гораздо чаще также новая версия пытается воссоздавать различные диаграммы и схемы на основе фонового рисунка, а не из отдельных графических и текстовых блоков.
Есть еще несколько новинок, призванных повысить в Abbyy FineReader 12 Professional качество распознавания. Как известно, одной из предпосылок для этого является качество оригинала, особенно если он получен с помощью не сканера, а фотокамеры. Именно поэтому в свое время в FineReader появились средства предварительной обработки оригиналов. В новой версии их список расширен, добавились обрезка по краям страниц, осветление и выравнивание яркости фона, удаление цветных элементов. Последнее может пригодиться, к примеру, для обработки документов с печатями и штампами. Кроме того, теперь пользователь может подключать различные методы индивидуально.

Улучшена также языковая поддержка. Во-первых, появился русский алфавит с ударениями, во-вторых, декларируется повышение качества распознавания китайского, японского и корейского (до 20%), арабского (до 60%), иврита (до 10%) - достигнуто это, по-видимому, за счет совершенствования и дополнительной тренировки классификаторов .

Ну и наконец, один из наиболее животрепещущих вопросов для многих читателей: выросла ли скорость работы программы? Аргументированно ответить на этот вопрос, тем более с цифрами, не так-то просто - слишком много языков, каждый из которых имеет свои нюансы; слишком велико разнообразие оригиналов; слишком много неизвестных нам факторов влияния на работу алгоритмов. Поэтому даже сами разработчики достаточно сдержанно говорят о росте производительности Abbyy FineReader 12 Professional на 10-15%.
Подобные цифры обычно получаются по результатам обработки достаточно больших массивов документов и, соответственно, представляют собой нечто вроде «средней температуры по больнице». Поэтому полезно подробнее изучить какие-нибудь показательные частные случаи, к примеру, подобные двум следующим:
Оба документа распознавались в цветном режиме, а второй также и в черно-белом, что имело целью имитировать процесс подготовки электронной книги. Все настройки по умолчанию оставлялись без изменений, за исключением набора языков и, соответственно, режимов работы. В качестве тестового полигона использовался ПК с процессором i5-3450 и 8 ГБ памяти. Результаты представлены в следующей таблице:
Как видно, для PDF ускорение даже превышает обещанные 15% - возможно, это как раз один из особых случаев, хорошо подходящих для последних оптимизаций в алгоритмах распознавания. При этом надо иметь в виду, что программы, вообще говоря, проделали разный объем работы. Взгляните хотя бы на иллюстрации выше к обработке таблиц - трудно сказать, какой из версий пришлось сложнее.
Что касается количества ошибок, то оно у обеих версий практически совпадало, хотя было заметно, что иногда сомнения вызывают разные фрагменты и символы - это, по-видимому, является свидетельством тренировки алгоритмов. В любом случае, большинство неуверенно распознанных символов абсолютно корректно идентифицировалось с помощью словарей, а «грубые» ошибки (некорректная интерпретация специальных и декоративных символов, текста на графике и пр.) совпадали. Так что разницу и вовсе можно считать исчезающей.
Другой вопрос, насколько подобное повышение производительности вообще имеет значение? По-видимому, выигрыш в полминуты на 138 страницах, которые все равно нужно проверять и, возможно, корректировать, немногого стоит. Если работы, подобные тестовым заданиям, предполагается выполнять от случая к случаю, то о производительности можно точно не переживать. Другое дело, если речь идет об автономной обработке больших объемов документов, которая доступна в Abbyy FineReader 12 Corporate. В таком случае экономия 15% времени уже вполне ощутима.
Несмотря на то, что новый Abbyy FineReader 12 Professional не обещал ничего революционного, по крайней мере несколько изменений в нем заслуживают всяческой похвалы. Прежде всего, это усовершенствования технологии ADRT в части распознавания таблиц, диаграмм и вообще логической структуры страниц, что в некоторых случаях позволяет получать кардинально лучшие результаты, а также фоновый режим обработки, который открывает новые возможности для интерактивной работы с большими документами.
Других изменений также немало, хотя они и менее значимы. Движение в сторону поддержки сенсорного управления сегодня безусловно оправдано, однако путь выбран порочный - обеспечить в одном интерфейсе одинаково удобную работу мышью и пальцами вряд ли возможно. Впрочем, пока Windows-планшеты только пытаются пробиться на рынок, и у разработчиков из Abbyy еще есть время.
Цены на Abbyy FineReader 12 Professional:
Как обычно, ответ на вопрос «стоит ли менять старую версию на новую?» зависит от ситуации. В любом случае стоит учитывать, что жизненный цикл у FineReader достаточно продолжительный, и если какое-то из описанных улучшений играет для вас сколько-нибудь существенную роль, то за 2-3 года затраты на обновление наверняка окупятся - если не материально, то морально. Решить же для себя этот вопрос окончательно поможет .
Хотя авансы, выданные искусственному интеллекту (ИИ) за последние 50 лет, ни на йоту не приблизили «умные» машины к когнитивным возможностям человека, полностью отрицать успехи в данном направлении было бы несправедливо. Наиболее очевидный и яркий пример - шахматы (не говоря уже о более простых играх). Компьютер пока не может имитировать наше мышление, но он вполне способен компенсировать данный пробел большим объемом специализированной памяти и скоростью перебора. Владимир Крамник охарактеризовал игру победившей его в 2006 г. программы Deep Fritz как «нечеловеческую» в том смысле, что она зачастую противоречила устоявшимся (человеческим) правилам стратегии и тактики.
А чуть более года назад очередное детище IBM, в свое время положившей начало триумфальным шахматным победам компьютеров (знаменитый Deep Blue), под названием Watson совершило новый прорыв, с большим отрывом победив сразу двух чемпионов популярной американской викторины Jeopardy. Показательно, однако, что хотя Watson самостоятельно озвучивал ответы, вопросы ему все же передавались в текстовом виде. Это говорит о том, что успехи во многих сферах приложения ИИ - распознавании речи и образов, машинном переводе - достаточно скромны, хотя это и не мешает нам уже сегодня применять их на практике. Наибольшие же успехи, пожалуй, демонстрируют системы оптического распознавания символов (OCR, Optical Character Recognition), с которыми наверняка так или иначе знакомы почти все пользователи ПК. Тем более, что российские разработки в данной области занимают достойное место в мире - я имею в виду ABBYY FineReader.
Текущая версия ABBYY FineReader имеет номер 11, т. е. приложение прошло достаточно долгий путь развития, и даже история этого процесса представляет определенный интерес. Не претендуя на исчерпывающую летопись, приведу лишь основные вехи за последнее десятилетие, в течение которого я более-менее следил за FineReader:
| Год | Версия | Главные особенности |
| 2003 | 7.0 | Прирост точности распознавания до 25%. Больше всего это отразилось на таблицах, особенно сложных, с окрашенными ячейками, скрытыми разделителями и пр. |
| 2005 | 8.0 | Дальнейшая оптимизация алгоритмов распознавания, в первую очередь направленная на работу не со сканами документов, а с цифровыми фотографиями. Для этого появились дополнительные функции подготовки оригиналов (устранение искажений, выравнивание строк и пр.). |
| 2007 | 9.0 | Появление технологии ADRT, которая учитывает логическую структуру всего обрабатываемого (многостраничного) документа и умеет выделять повторяющиеся элементы (колонтитулы), соединять «перетекающие» объекты (таблицы) и пр. |
| 2009 | 10.0 | Дальнейшее совершенствование ADRT и алгоритмов распознавания, повышение точности обработки оригиналов с низким разрешением до 30%. |
| 2011 | 11.0 | Основное внимание уделено скорости работы программы. «Второе пришествие» черно-белого режима, который на оригиналах хорошего качества дает дополнительное ускорение до 30%. |
Естественно, за это же время в FineReader расширялась поддержка форматов документов, совершенствовались встроенные инструменты и интерфейс, улучшалось воссоздание структуры оригиналов и т. п. Однако выделенные моменты непосредственно связаны с технологиями OCR и неплохо демонстрируют скачкообразный процесс развития, характерный для сложных наукоемких систем, когда после очередного «прорыва» следует некоторый период «затишья», необходимый для совершенствования новых алгоритмов. Они-то и представляют главную ценность любой OCR-программы, и поэтому сколько-нибудь подробная информация о них крайне редко доходит до пользователей. Однако компания ABBYY любезно согласилась приоткрыть завесу тайны, и сегодня мы имеем возможность заглянуть в святая святых FineReader.
Итак, поскольку OCR относится к области ИИ, вполне логично, что разработчики стремятся хоть в какой-то степени имитировать деятельность нашего мозга. Конечно, устройство нашей зрительной системы невероятно сложно, но базовые «крупноблочные» принципы ее функционирования достаточно изучены, обычно их выделяют три:
FineReader - единственная в мире OCR-система, которая действует в соответствии с вышеописанными принципами на всех этапах обработки документа. Соответствующая технология носит название IPA - по первым буквам английских терминов. К примеру, согласно принципу целостности, фрагмент изображения будет интерпретироваться как символ, только если в нем присутствуют все структурные части подобных объектов, причем находящиеся в определенных взаимоотношениях. Это помогает заменить перебор большого числа эталонов (в поисках более-менее подходящего) целенаправленной проверкой разумного количества гипотез, причем опираясь на накопленные ранее сведения о возможных начертаниях символа в распознаваемом документе.
Однако принципы IPA применяются при анализе не только фрагментов, соответствующих (предположительно) отдельным символам, но и всего исходного изображения страницы. Большинство OCR-систем основываются на распознавании иерархической структуры документа, т. е. страница разбивается на основные структурные элементы, такие как таблицы, изображения, блоки текста, которые, в свою очередь, разделяются на другие характерные объекты - ячейки, абзацы - и так далее, вплоть до отдельных символов.
Такой анализ может проводиться двумя основными способами: сверху-вниз, т. е. от составных элементов к отдельным символам, или, наоборот, снизу-вверх. Чаще всего применяется один из них, но в ABBYY разработали специальный алгоритм MDA (multilevel document analysis, многоуровневый анализ документа), который сочетает оба. Вкратце он выглядит следующим образом: структура страницы анализируется методом сверху-вниз, а воссоздание электронного документа по окончании распознавания происходит снизу-вверх, однако на всех уровнях дополнительно действует механизм обратной связи. В результате резко снижается вероятность грубых ошибок, связанных с неверным распознаванием высокоуровневых объектов.
Исторически OCR-системы развивались от распознавания отдельных символов. Эта задача и до сих пор является важнейшей и самой трудной, именно с ней связаны наиболее сложные алгоритмы. Однако вскоре стало понятно, что в ее решении может помочь более высокоуровневая информация (к примеру, о языке документа и правильности написания распознанных слов) - так появились контекстная и словарная проверки. Затем стремление сохранять форматирование и воссоздавать физическую структуру (т. е. взаимное расположение различных объектов) документа привело к необходимости подробного анализа целой страницы. Понятно, что это также заметно влияет на общее качество распознавания, поскольку помогает корректно обрабатывать многоколоночную верстку, таблицы и другие приемы «нелинейного» расположения текста.
Большинство современных OCR действуют именно на этих трех уровнях - символов, слов, страниц, - практикуя, как уже было сказано, подходы сверху-вниз или снизу-вверх. Однако ABBYY, в соответствии с принципами IPA, ввела в FineReader еще один уровень - всего многостраничного документа. Прежде всего это понадобилось для корректного воспроизведения логической структуры, которая в современных документах становится все сложнее. Но есть и дополнительные бонусы: повышение точности и ускорение обработки повторяющихся объектов, более корректная идентификация (а значит, и распознавание) «перетекающих» со страницы на страницу объектов.
Именно для этого и была разработана ADRT (Adaptive Document Recognition Technology) - технология анализа и синтеза документа на логическом уровне. В конечном итоге она помогает сделать результат работы FineReader максимально похожим на оригинал. Для этого анализируется изображение всего документа, а распознанные слова объединяются в группы (кластеры) в зависимости от начертания, окружения и местоположения на странице. Таким образом программа как бы видит «логику» разметки документа и в дальнейшем может унифицировать оформление результата.
Благодаря ADRT, FineReader, начиная с версии 9.0, научился обнаруживать, распознавать и воспроизводить следующие структурные части и элементы форматирования документа:
В соответствии с алгоритмом MDA, собственно распознавание начинается сверху-вниз, с уровня страницы. Понятно, что чем больше неверных решений будет сделано на ранних этапах этого процесса, тем больше будет на следующих. Именно поэтому точность распознавания так сильно зависит от качества оригиналов, но и алгоритмы их предварительной обработки могут иметь существенное значение. Так, по мере роста популярности цветных документов в FineReader появилась процедура адаптивной бинаризации (adaptive binarization, AB ). Если отсканировать сразу в черно-белом режиме документ, где присутствуют водяные знаки либо текст расположен на текстурной или цветной подложке, то на изображении неизменно появится «мусор», который затем будет довольно сложно отделить от «полезного» изображения (т. к. исходная информация о нем уже потеряна). Именно поэтому FineReader предпочитает работать с цветными или полутоновыми изображениями, самостоятельно преобразуя их в черно-белые (этот процесс и называется бинаризацией). Но и это не всё. Поскольку цвета текста и фона могут различаться в пределах страницы и даже отдельных строк, AB выделяет слова с более-менее одинаковыми характеристиками и подбирает для каждого оптимальные с точки зрения качества распознавания параметры бинаризации. Именно в этом и состоит адаптивность алгоритма, который, таким образом, является примером использования обратной связи в MDA. Понятно, что эффективность AB сильно зависит от оформления исходных документов - на тестовой базе ABBYY этот алгоритм обеспечил повышение точности распознавания на 14,5%.
Но наиболее интересное, конечно, начинается, когда процесс распознавания опускается на самые нижние уровни. Так называемая процедура линейного деления разбивает строки на слова, а слова на отдельные буквы; далее, в соответствии с принципом IPA, формирует набор гипотез (т. е. возможных вариантов того, что́ это за символ, на какие символы разбито слово и т. д.) и, снабдив каждую оценкой вероятности, передает на вход механизма распознавания символов. Последний состоит из ряда так называемых классификаторов , каждый из которых также формирует ряд гипотез, ранжированных по предполагаемой степени вероятности. Важнейшей характеристикой любого классификатора является среднее положение правильной гипотезы. Понятно, что чем выше она находится, тем меньше работы для последующих алгоритмов - к примеру, словарной проверки. Но для достаточно отлаженных классификаторов чаще всего оценивают такие характеристики, как точность распознавания по первым трем гипотезам или только по первой - т. е., грубо говоря, способность угадать верный ответ с трех или с одной попытки. ABBYY в своих системах применяет следующие типы классификаторов: растровый, признаковый, признаковый дифференциальный, контурный, структурный и структурный дифференциальный - которые сгруппированы на двух логических уровнях.
Принцип действия РК , или растрового классификатора, основан на попиксельном сравнении изображения символа с эталонами. Последние формируются в результате усреднения изображений из обучающей выборки и приводятся к некой стандартной форме; соответственно, для распознаваемого изображения также предварительно нормализуются размер, толщина элементов, наклон. Этот классификатор отличается простотой реализации, скоростью работы и устойчивостью к дефектам изображений, но обеспечивает сравнительно низкую точность и именно поэтому используется на первом этапе - для быстрого порождения списка гипотез.
Признаковый классификатор (ПК ), как и следует из его названия, основывается на наличии в изображении признаков того или иного символа. Если всего таких признаков N, то каждую гипотезу можно представить точкой в N-мерном пространстве; соответственно, точность гипотезы будет оцениваться расстоянием от нее до точки, соответствующей эталону (который также нарабатывается на обучающей выборке). Понятно, что типы и количество признаков в значительной степени определяют качество распознавания, поэтому обычно их достаточно много. Этот классификатор также сравнительно быстр и прост, но не слишком устойчив к различным дефектам изображения. Кроме того, ПК оперирует не исходным изображением, а некой моделью, абстракцией, т. е. не учитывает часть информации: скажем, сам факт наличия каких-то важных элементов ничего не говорит об их взаимном расположении. По этой причине ПК используется не вместо, а вместе с РК.
Контурный классификатор (КК ) представляет собой частный случай ПК и отличается тем, что анализирует контуры предполагаемого символа, выделенные из исходного изображения. В общем случае его точность ниже, чем у полновесного ПК.
Признаковый дифференциальный классификатор (ПДК ) также похож на ПК, однако используется исключительно для различения похожих друг на друга объектов, таких как «m» и «rn». Соответственно, он анализирует только те области, где скрываются отличия, а на вход ему подаются не только исходные изображения, но и гипотезы, сформированные на ранних стадиях распознавания. Принцип его работы, однако, несколько отличается от ПК. На этапе обучения в N-мерном пространстве формируются два «облака» (групп точек) возможных значений для каждого из двух вариантов, затем строится гиперплоскость, отделяющая «облака» друг от друга и примерно равноудаленная от них. Результат распознавания зависит от того, в какое полупространство попадает точка, соответствующая исходному изображению.
Сам по себе ПДК не выдвигает гипотез, а лишь уточняет имеющиеся (список которых в общем случае сортируется пузырьковым методом), так что прямая оценка его эффективности не проводится, а косвенно ее приравнивают к характеристикам всего первого уровня OCR-распознавания. Однако понятно, что она зависит от корректности подобранных признаков и представительности выборки эталонов, обеспечение чего является достаточно трудоемкой задачей.
Структурно-дифференциальный классификатор (СДК ) первоначально применялся для обработки рукописных текстов. Его задача состоит в различении таких похожих объектов, как «C» и «G». Таким образом, СДК основывается на признаках, характерных для каждой пары символов, процесс его обучения еще сложнее, чем у ПДК, а скорость работы ниже, чем у всех предыдущих классификаторов.
Структурный классификатор (СК ) является предметом гордости компании ABBYY, первоначально он был разработан для распознавания так называемого рукопечатного текста, т. е. когда человек пишет «печатными» буквами, но впоследствии был применен и для печатного. Он используется на завершающих этапах распознавания и вступает в действие достаточно редко, а именно, только в том случае, когда до него доходят как минимум две гипотезы с достаточно высокими вероятностями.
Качественные характеристики всех классификаторов собраны в следующую таблицу. Они, впрочем, позволяют лишь оценить эффективность алгоритмов друг относительно друга, т. к. не являются абсолютными, а получены на основе обработки конкретной тестовой выборки. Может создаться впечатление, что на последних этапах распознавания борьба идет буквально за доли процента, но на самом деле каждый классификатор вносит существенную лепту в повышение точности распознавания - так, к примеру, СК снижает количество ошибок на ощутимые 20%.
| РК | ПК | КК | ПДК* | СДК** | СК** | |
| Точность по первым трем вариантам, % | 99,29 | 99,81 | 99,30 | 99,87 | 99,88 | - |
| Точность по первому варианту, % | 97,57 | 99,13 | 95,10 | 99,26 | 99,69 | 99,73 |
* оценка всего первого уровня OCR-алгоритма ABBYY
** оценка для всего алгоритма после добавления соответствующего классификатора
Любопытно, однако, что, несмотря на довольно высокую точность, алгоритм собственно распознавания не принимает окончательного решения. В соответствии с принципом MDA, гипотезы выдвигаются на каждом логическом уровне, и число их может расти в геометрической прогрессии. Соответственно, последовательная проверка всех гипотез вряд ли окажется эффективной, и потому в OCR-системах ABBYY применяется метод структурирования гипотез, т. е. отнесения их к тем или иным моделям. Последних существует пара десятков, вот только несколько их типов: словарное слово, несловарное слово, арабские цифры, римские цифры, URL, регулярное выражение - а в каждый может входить множество конкретных моделей (к примеру, слово на одном из известных языков, латиницей, кириллицей и т. д.).
Все финальные действия выполняются уже именно с гипотезами, построенными по моделям. К примеру, контекстная проверка определит язык документа и сразу же существенно понизит вероятность моделей с использованием неправильных алфавитов, а словарная компенсирует погрешности при неуверенном распознавании некоторых символов: так, слово «turn» присутствует в словаре английского языка - в отличие от «tum» (во всяком случае, оно отсутствует среди популярных). Хотя приоритет словаря выше, чем у любого классификатора, он не обязательно является последней инстанцией, и в общем случае не останавливает дальнейшие проверки: во-первых, как говорилось выше, имеется модель несловарного слова, во-вторых, специальная организация словарей позволяет с высокой долей вероятности предположить, может ли какое-то неизвестное слово относиться к тому или иному языку. Тем не менее, словарная проверка (и полнота словарей) оказывает существенное влияние на результат распознавания, и в тестах самой ABBYY сокращает количество ошибок практически вдвое.
Печатные документы - далеко не единственные, представляющие интерес с точки зрения их оцифровки и автоматической обработки. Довольно часто приходится работать с формами, т. е. документами с предопределенными и фиксированными полями, которые заполняются вручную, но сравнительно аккуратно (так называемыми рукопечатными символами) - примером могут служить различные анкеты. Технология их обработки имеет отдельное название - ICR (intelligent character recognition) - и достаточно существенно отличается от OCR. Так, поскольку в данном случае задача состоит не в воссоздании всего документа, а в извлечении из него конкретных данных, то она распадается на две основные подзадачи: нахождение нужных полей и собственно распознавание их содержимого.
Это достаточно специфическая область, и ABBYY предлагает для нее совершенно отдельный программный продукт ABBYY FlexiCapture. Он предназначен для создания автоматизированных и полуавтоматизированных систем, предполагает настройку на конкретные типы документов, для которых создаются специальные шаблоны, умеет интеллектуально находить на страницах различные поля и верифицировать данные в них и т. д. Однако в самой основе лежат алгоритмы распознавания символов, аналогичные тем, что применяются в FineReader, да и общая схема весьма похожа:
Впрочем, важное отличие все же имеется: структурный классификатор является обязательным участником процесса - это связано со спецификой рукопечатных символов. Кроме того, ICR предполагает большое число специфических дополнительных проверок: например, не является ли символ зачеркнутым, или действительно ли распознанные символы формируют дату.
Работа по распознаванию изображений состоит из следующих этапов:
При распознавании текстов возможны два варианта: или вы сканируете материал сами, или работаете с уже отсканированным текстом.
В первом случае этапы «Получить изображения» и «Открыть изображения» объединяются в одно - FineReader полученные сканы сразу же открывает в своем пакете. Во втором случае этап «Получить изображения» уже пройден, надо только открыть их в программе.
Рассмотрим оба варианта по очереди.
Сканирование запускается через «Файл → Сканировать страницы» или кнопкой меню «Сканировать», или Ctrl-K.
Рис. 1 Интерфейс сканирования
Однако, прежде чем начинать сканировать, неплохо бы разобраться, как получить сканы, наиболее оптимальные для распознавания. А для этого понять, чем «хороший» (с точки зрения FineReader) скан отличается от «не очень хорошего».
Для качественного распознавания программе требуется три вещи. Во-первых, возможность надежно отличить текст и иллюстрации от фона страницы. Во-вторых, чтобы буквы, цифры и прочее содержимое были четкими и разборчивыми, чтобы не возникало ситуаций «здесь и человеческий глаз не всегда поймет, что именно напечатано». В-третьих, строки текста на скане должны идти так же ровно, как они напечатаны на странице книги, без перекосов и искажений. Есть еще и другие требования к качественному скану, но эти можно считать ключевыми.
1. Для надежного различения «здесь текст, а здесь фон страницы» требуется, чтобы переход между тем и другим был резким, не размытым. Вот образцы страниц с плохой и с хорошей четкостью. Во первом случае, естественно, будет распознаваться хуже, с большим количеством ошибок.

Рис. 2. Размытые границы литер

Рис. 3. Четкие границы литер
Обычная причина размытых границ «текст-фон» - сканирование с нарушенной фокусировкой, то, что обычно называют «не в фокусе». Поэтому перед началом работы желательно проверить ваш сканер на этот момент.
Другая причина, которая может помешать различению текста и фона - слишком «плотный» фон страницы. В норме он должен быть или чисто белым, или белым с небольшой примесью какого-нибудь цвета. Если сканируются книги старых изданий, где бумага часто бывает пожелтевшей, то фон тоже может быть желтоватый (но умеренно).
Если же фон выглядит заметно перетемненным, то такие страницы опять же будут распознаваться хуже.
То, какой вид будет у фона, зависит от выставленной яркости сканирования. Ее можно регулировать через движок «Яркость». Для начала имеет смысл поставить 50%, проверить, что при этом будет, при необходимости поправить.
2. Разборчивость литер текста в основном зависит от яркости и от разрешения сканирования.
Если яркость слишком велика, линии букв будут будут рваными, они станут как бы рассыпаться на отдельные кусочки. Если яркость мала, то детали букв начинают сливаться между собой, возникают бесформенные пятна. И то, и другое для программ распознавания не очень-то съедобная «пища».
Яркость здесь настраивается так же, как и в предыдущем случае - ставим для начала в интерфейсе сканирования 50%, а дальше по ситуации.

Рис. 4. Страница со слишком большой яркостью

Рис. 5. Страница со слишком маленькой яркостью (перетемненный фон страницы)

Рис. 6. А вот эта же страница, но в нормальном виде
Разрешение сканирования определяет сколько пикселей в скане будет приходиться на каждую букву. Если этих пикселей достаточно для отрисовки контура буквы, то проблем при распознавании не будет. Если же недостаточно, то буквы могут стать плохо различимыми даже для человеческого глаза, не говоря уже о программах распознавания.

Рис. 8. То же самое, но на 200 точек

Рис. 9. То же самое, но на 400 точек
При выборе разрешения обычно руководствуются следующими правилами:
Интерфейс сканирования в FineReader позволяет выбирать только 300 точек или 600 (строка «Разрешение»). Поэтому если у вас много материала, который желательно делать на 400 точек, то лучше сканировать не из-под FineReader, а из программы, идущей вместе со сканером.
Или же в настройках FineReader переключиться с собственного интерфейса программы на TWAIN-интерфейс вашего сканера («Сервис → Настройки → закладка «Сканировать/Открыть» → щелкнуть внизу по «Использовать интерфейс сканера»). Тогда вы сможете сканировать из FineReader, но работать будете в интерфейсе сканера (обычно там больший объем настроек и функций).
3. Ровные, аккуратно выглядящие строчки текста в основном обеспечиваются предобработкой изображения («пред-» в данном случае означает «выполняемое после сканирования, но перед распознаванием»). После правильно сделанной предобработки содержимое страниц будет распознаваться с более высоким качеством.
FineReader для этого имеет достаточно богатый набор функций, который можно увидеть в настройках программы, на закладке «Сканировать/Открыть». Также это окошко можно вызвать через кнопку «Настройки» в окошке интерфейса сканирования.

Рис. 10. Настройки предобработки
«Делить разворот книги» надо выбирать, когда книга сканировалась не постранично, а разворотами. Тогда для распознавания они будут нарезаны постранично.
«Определять ориентацию страниц» используется в том случае, если книга сканировалась повернутой набок. Тогда она будет развернута в свое нормальное положение. Но если в книге есть страницы, которые напечатаны повернутыми на 90 градусов относительно основной массы, то галочку здесь лучше снять. Иначе при выводе распознанного в PDF вы можете получить часть страниц в «книжной» ориентации, а часть - в «альбомной». Повернуть нужные страницы в этом случае лучше вручную, во встроенном редакторе изображений
«Исправить перекосы» устраняет перекосы страниц. Настройка однозначно необходимая, но надо иметь в виду, что PDF «Текст под изображением страницы», полученный из таких сканов, будет иметь не совсем аккуратный вид - сероватые клинья по краям страницы (там где делался поворот).
«Исправить искажения строк» выравнивает изгибы строк, которые при сканировании часто образуются около переплета (их еще называют «усы»).

Рис. 11. Пример страницы с изгибами строк
«Устранить трапециевидные искажения» исправляет деформации страниц, появляющиеся если книга не очень плотно прижата к стеклу сканера.
«Инвертировать изображения» необходима, если в сканируемом материале много текста «светлые буквы на темном фоне» и вы хотите преобразовать их в обычное «темные буквы на светлом фоне».
«Удалить цветные элементы» полезно, если на странице вида «черные буквы на белом фоне» надо убрать разные ненужности, вроде пометок ручкой на полях, подписей и печатей (офисная документация), а то и просто пятен. Но если на этой же странице есть какие-то сделанные в цвете «нужности» - графики, диаграммы или фотографии, то галочку ставить нельзя. Иначе будут удалены и они.
«Исправить разрешение изображений» - пункт, требующий более развернутого пояснения, чем предыдущие. Дело в том, что процесс распознавания в FineReader очень чувствителен к тому, какое разрешение выставлено в свойствах данного изображения. От этого существенно зависит то, насколько точно будут определены кегли букв текста, межбуквенные и межстрочные расстояния и прочее подобное. Поэтому галочка здесь необходима. Кроме того, не стоит удивляться, если по ходу распознавания вы будете постоянно получать сообщения FineReader «на странице такой-то неправильно выставлено разрешение и хорошо бы его исправить».
Кроме настроек предобработки на закладке «Сканировать/Открыть» есть блок настроек «Общее». Здесь задается набор основных действий, которые будут выполнены над открываемыми страницами. Варианты таких действий могут быть следующие:

Рис. 12. Пример страницы со сложной версткой

Рис. 13. Пример страницы со сложной версткой
Это второй вариант работы с изображениями: не сканировать их самому, а получить в уже готовом виде и открыть в FineReader. Делается через кнопку «Открыть» в меню основного окна или через «Файл → Открыть PDF или изображение», или через Ctrl-O.

Рис. 14. Окно «Открыть изображение»
В открывшемся окошке Проводника выбираете изображения, задаёте необходимые настройки (кнопка «Настройки») и нажимаете «Открыть». Настройки здесь используются те же самые, что описаны для сканирования, работать с ними надо так же.
Когда страницы открыты в FineReader, то пакет по умолчанию создается безымянным («Документ без имени») и хранится в TMP-папке, только в пределах текущего сеанса работы. Чтобы случайно не потерять результаты работы, рекомендуется сразу же после создания сохранить пакет под каким-нибудь постоянным именем («Файл → Сохранить документ FineReader»).
После того, как вы открыли сканы, надо выполнить разметку страниц на блоки. Это делается через «Документ → Анализ документа» или через Ctrl-Shift-E.
Основных рабочих целей у разметки две.
Во-первых, отделить то, что на странице есть текст, от того, что текстом не является. «Текстом» в данном случае считается все, что FineReader в состоянии распознать. «Не-текстом» соответственно считается все, что он распознать не в состоянии. В основном это иллюстративная часть страницы - рисунки, чертежи, графики, диаграммы и прочее подобное. Формулы, рукописные записи и ноты с этой точки зрения тоже считаются не-текстом - распознавать их FineReader пока не умеет. А значит при разметке их надо пометить, как «картинка».
Во-вторых, еще надо то, что есть текст, разметить по категориям - просто текст, таблицы, примечания (сноски), колонтитулы, оглавления и тому подобное. Чтобы потом, когда вы будете читать распознанное в текстовом редакторе, все эти элементы выглядели бы именно так, как вы и привыкли (были бы отформатированы соответствующим образом).
Размеченная страница может иметь примерно следующий вид:

Рис. 15. Окно «Изображение» с размеченной страницей
Теперь надо просмотреть разметку, сделанную программой на каждой из страниц и при необходимости поправить ее.
Погрешности разметки обычно бывают следующих видов.
1. Какая-то часть содержимого страницы (текст, рисунок и т. д.) выделена правильно в смысле границ области, но ей присвоено не то содержимое. Например, фрагмент текста размечен, как рисунок или наоборот.
В этом случае надо щелкнуть мышью по такой области, открыть контекстное меню, выбрать в нем «Изменить тип области», в открывшейся подменюшке выбрать требуемый тип («Текст», «Таблица», «Картинка», «Фоновая картинка», «Штрих-код»).

Рис. 16. Контекстное меню «Изменить тип области»
Быстро посмотреть где какая область можно по цвету рамок. «Текст» выделяется рамками темно-зеленого цвета, «Таблица» - синего, «Картинка» - светло-красного, «Фоновая картинка» - темно-красного, «Штрих-код» - светло-зеленого.
2. В смысле содержимого область выделена правильно, но в смысле размеров (границ) выделено не все, что в данном случае требовалось. Или же наоборот - попал кусок от соседней области с другим содержимым.

Рис. 17. Страница с некорректно сделанной разметкой
К верхней области «картинка» прихвачены окружающие ее подписи (должны быть размечены, как «текст»).
В нижнюю область «картинка» при разметке не попала часть изображения.
Чтобы это поправить, надо сначала щелкнуть в окошке «Изображение» по кнопке «Стрелка».
А затем щелкать по каждой неправильно размеченной области и перемещать ее границы. Примерно таким же образом, как обычно перемещают границы окошек открытых программ.
3. Какая-то часть содержимого страницы разметкой вообще пропущена, не попала ни в одну из созданных областей.

Рис. 18. Из разметки выпала формула (не попала ни в один из блоков)
Здесь надо будет создать на странице новую область (выделить пропущенную часть страницы рамкой), а затем присвоить созданной области нужный тип.
Для этого надо сначала щелкнуть в окошке «Изображение» по значку «Выделить зону распознавания»
После этого обвести нужный участок рамкой (как обычно в графическом редакторе выделяют часть рисунка) и наконец задать тип области. Последняя операция уже описана в пункте 1.
Если текстовая часть страницы вам нужна просто, как сплошной текст (что чаще всего и бывает), то этого вполне достаточно. Если же вы хотите, чтобы в Word различные элементы оформления распознанных страниц (примечания, колонтитулы) выглядели бы именно, как примечания и колонтитулы, то надо проверить и этот момент.
Регулируется он через контекстное меню. Щелкаете по нужной области «Текст» на проверяемой странице, в контекстном меню выбираете пункт «Назначение текста», внутри его подменюшки смотрите против какого пункта стоит галочка (обычно это «Автоопределение»). Если стоит не там, где надо, переключаетесь на нужный элемент.

Рис. 19. Контекстное меню «Назначение текста»
После того, как исправлены ошибки в разметке, можно запускать распознавание. Это делается через «Документ → Распознать документ» или через Ctrl-Shift-R. Перед этим не забудьте выставить язык распознавания и задать необходимые настройки.
Язык выставляется через окошко «Язык документа» в панели кнопок основного окна программы.

Рис. 20. Выбор языка через основное меню
Или в настройках («Сервис → Настройки → закладка «Документ»).

Рис. 21. Выбор языка через настройки FineReader
Если в открывшемся списке нет нужного вам языка, то нажмите «Выбор языков» в нижней части списка и в открывшемся окошке поставьте галочку против необходимого вам языка (набора языков). После этого он будет добавлен в список.
В настройках распознавания («Сервис → Настройки → закладка «Распознать») режим распознавания лучше оставить в умолчательном значении («Тщательное распознавание»). «Быстрое распознавание» имеет смысл ставить только если у вас что-то несложное по виду и с очень хорошим качеством сканирования. Например, отсканированная в черно-белом распечатка текстового документа без иллюстраций.

Рис. 22. Настройки, закладка «Распознать»
Из остальных настроек основное значение имеет группа «Определение структурных элементов». Здесь перечислены детали оформления страниц: сноски (примечания), колонтитулы, списки, оглавления. Когда против элемента поставлена галочка, он будет распознан и сохранен в DOC/RTF/DOCX не просто как часть текста на странице, а именно, как сноска, колонтитул, список или оглавление.
Только не забудьте при этом важный момент. Если вам приходится распознавать области с подобным содержимым, то одной галочки в настройках закладки «Распознать» может оказаться мало. Кроме этого еще требуется на этапе разметки правильно пометить эти области маркером «Назначение текста» из контекстного меню.
Вычитку распознанного текста в FineReader можно делать двумя способами. Или с помощью функции «Проверка», или обычным образом, просматривая страницы во встроенном редакторе FineReader. Через окно «Крупный план» сверяем со сканом, где есть ошибки - исправляем.
Функция «Проверка» запускается кнопкой в правом верхнем углу меню или через Ctrl-F7. Ее работа построена на том, что во время распознавания FineReader помечает символы и слова, которые были распознаны с недостаточно высоким уровнем достоверности. То есть, у программы по их поводу есть некоторое сомнение «может это действительно тот символ, который вам предъявлен, но может быть и что-то другое». Во время проверки такие сомнительные места по очереди показываются пользователю, чтобы он при необходимости их поправил.
Окно проверки устроено достаточно просто. В верхней его части показывается фрагмент страницы, в котором находится проверяемый символ. В нижней части выводится строка распознанного текста с этим символом, а также расположены несколько кнопок для несложного редактирования.

Рис. 23. Окно «Проверка»
Если все порядке, символ определен правильно, то нажимаем на «Пропустить». Если он определен неверно, то вводим правильное значение или с помощью клавиатуры, или если на клавиатуре такого нет, то с помощью кнопки «Вставить символ» (греческая буква «омега»). После чего нажимаем на «Подтвердить».
Аналогичным образом действуем если символ распознан верно, а вот его форматирование - неверно. Например в тексте книги в каком-то месте идет курсив, а распознался он, как обычный шрифт. Для переформатирования используем кнопки в нижней части окна.
Но возможности окна проверки все-таки достаточно ограничены. И по тому, какого размера кусочек страницы может быть показан в верхней части окна, и по возможностям редактирования, которые здесь имеются. Поэтому все перемещения по тексту, от одной точки проверки до другой, отслеживаются еще и в окнах «Текст» и «Крупный план». Все время, пока идет работа, курсоры в «Тексте» и «Крупном плане» перемещаются синхронно их положению в «Проверке».
Если в проверяемом фрагменте страницы (в его скане) вдруг потребовалось увидеть больше, чем несколько слов, показанных в «Проверке», то можно это сделать в «Крупном плане». Если для правки текущей ошибки требуются возможности редактора из «Текста», то можно на время переключиться в него (просто щелкнув по его окошку), сделать необходимую работу и вернуться обратно в «Проверку» (щелкнув по ее окошку). После возвращения в «Проверку», там будут отображены все изменения, которые вы сделали в «Тексте».

Рис. 24. Пример работы в одновременно открытых окнах «Проверка», «Текст» и «Крупный план»
Если вам окошко «Проверка» с его ограниченными возможностями не очень-то удобно (привыкли работать со всеми удобствами текстовых редакторов и привычки менять не собираетесь), то можно с самого начала делать эту работу в окне «Текст».
Места, требующие проверки, там отображаются в полном объеме - это символы и слова, выделенные светло-голубым. Возможность перемещаться от ошибки к ошибке, не просматривая всю страницу целиком, тоже имеется - кнопки «Следующая ошибка» и «Предыдущая ошибка» на панели кнопок с левой стороны окна.
Теоретически, по замыслу создателей FineReader, окна «Проверка» должно быть вполне достаточно для полноценной вычитки распознанного текста. Все сомнительные места отмечены, движемся вдоль них, правим ошибки, на выходе получаем полностью вычищенный текст.
Но, как это часто бывает, теория здесь расходится с повседневной практикой работы. В распознанных текстах систематически встречаются ошибочные места, которые, как ошибки, не помечены. То есть FineReader распознает какой-то символ/слово неверно, но при этом с полной уверенностью, что распознал правильно.
Поэтому для полноценной вычитки одного только окна «Проверка» обычно бывает недостаточно - в особенности если в тексте много научных или технических терминов, профессионального жаргона и тому подобной «несловарности». Надо еще пройтись по распознанному вручную - внимательно просмотреть его в окне «Текст» и проверить все мало-мальски сомнительные места.
Вычитка текста в окне «Текст» мало чем отличается от обычной корректорской работы. Настраиваете окна «Текст» и «Крупный план» так, чтобы они занимали большую часть рабочего окна программы, переходите к очередной проверяемой странице, просматриваете ее текст. Если обнаруживаете сомнительное или явно ошибочное место, то щелкаете по нему - при этом курсор в «Крупном плане» устанавливается точно в том же самом месте оригинала (скана). Сравниваете оригинал и распознанное, при необходимости правите, двигаетесь дальше.

Рис. 25. Вычитка с помощью окон «Текст» и «Крупный план»
Функциональность редактора окна «Текст» ничем особо не отличается от функциональности любого текстового редактора средней степени сложности. Вид у кнопок в меню достаточно типовой, каких-либо проблем при работе с ними возникать не должно. Если надо поправить какой-то символ, который на клавиатуре отсутствует, то, как и в окошке «Проверка», надо нажать на кнопку с греческой «омегой» и в открывшейся таблице выбрать необходимое.
Когда отсканированный материал распознан и вычитан, его надо сохранить в одном из документальных форматов - DOC, DOCX, RTF, PDF, HTML и т. д. Это делается через «Файл → Сохранить документ как → выбрать нужный формат» или через кнопку «Сохранить» в основном меню FineReader.
В открывшемся окошке Проводника выбираете формат, через кнопку «Настройки» задаете параметры сохранения, нажимаете «ОК». Если хотите сразу же посмотреть нет ли заметных ошибок во внешнем виде сохраненного текста, то кроме этого поставьте галочку в «Открыть документ после сохранения». Тогда он сразу же будет открыт в редакторе (браузере, программе просмотра).

Рис. 26. Окно сохранения распознанного текста
Обычная практика распознавания - на вход поступает отсканированный текст книги или журнала, на выходе все его страницы сохраняются в файл с названием этой книги. Именно такая настройка «Создавать один файл для всех страниц» стоит по умолчанию в строке «Опции файла». Если же у вас распознается не какой-то цельный текст, а просто россыпь страниц (например офисная документация), то здесь надо будет выставить «Сохранять отдельный файл для каждой страницы».

Рис. 27. Настройки сохранения в DOC/DOCX/RTF
Ключевое и основное, что здесь надо выбрать - это с какой степенью точности в сохраняемом документе будет отображен внешний вид оригинала (один из режимов сохранения в окошке «Оформление документа»). Все остальные настройки - не более, чем уточнение и деталировка этого пункта.
Вариантов выбора здесь четыре: «Точная копия», «Редактируемая копия», «Форматированный текст» и «Простой текст».
1. «Точная копия».
По замыслу разработчиков здесь должно было быть практически зеркальное подобие распознаваемой страницы. Именно потому так и названо. С точным воспроизведением шрифтов, размеров букв (кеглей), расстояний между буквами в словах, расстояний между словами, строками и абзацами и других деталей верстки. Идея, в общем-то, неплохая, но возможности реализовать ее в задуманном объеме у FineReader обычно не хватает.
Шрифты и их начертание (Normal, Italic, Bold) часто воспроизводятся по принципу «как выйдет, так и получится». Могут быть переданы точно. Может случиться так, что шрифт, использованный на распознаваемой странице, будет замещен другим шрифтом (сходным по виду, но другим). Может случиться так, что начертание Normal будет распознано как Bold или же наоборот. И так далее, и тому подобное.
С воспроизведение кеглей, расстояний и прочего форматирования ситуация не намного лучше - более или менее точно воспроизвести внешний вид (верстку) распознаваемой страницы обычно удается лишь в случаях чего-нибудь не очень сложного.
В результате получается не очень понятно что - Word-документ, который можно только читать (ну и копировать оттуда текст). Редактировать его за пределами «пару букв убрать, пару букв вставить» малореально. А редактировать таки требуется - он ведь дальше пойдет в какую-то работу, а значит надо будет переделывать форматирование под потребности будущего использования.
С одной стороны весь текст здесь раскидан по многочисленным фреймам, что изрядно осложняет работу с ним. С другой стороны во время распознавания программа генерирует кучу Word’овских стилей - все форматирование в тексте делается исключительно через стили. Вполне обычно, когда на текст книги среднего размера (300-400 страниц) генерируется несколько сотен различных стилей. Что еще больше усложняет редактирование.
Резюме - выбирать этот режим сохранения особого смысла не имеет, работать с сохраненным текстом здесь достаточно неудобно.
Если же вам требуется полное воспроизведение внешнего вида оригинала, то это и проще, и практичнее сделать в виде PDF «Текст под изображением страницы» или же PDF «Только текст и картинки» (об этих способах вывода немного ниже).
2. «Редактируемая копия».
По смыслу это облегченная версия «Точной копии». Внешний вид оригинала воспроизводится не с такой степенью дотошности, как в предыдущем случае, фреймов с текстом заметно поменьше (хотя периодически попадаются). Однако, хоть этот вариант и называется «редактируемым», работать с ним тоже, не сказать чтобы удобно.
Если Word-документ нужен, как есть, только для просмотреть его его содержимое и скопировать нужный фрагмент текста, то вполне можно использовать и этот вариант. Если же требуется много переделывать, переформатировывать и так далее, то лучше выбирать что-то другое.
Причина та же самая - слишком много возни по преобразованию текста из того вида, который выдаст «Редактируемая копия», в тот вид, который может потребоваться вам. Все еще осталось какое-то количество текста во фреймах, в форматировании все еще сохраняется тенденция точно воспроизводить внешний вид (верстку) оригинала. Да и привычка генерировать кучу стилей никуда не делась.
Резюме - работать с текстом здесь не так хлопотно, как в «Точной копии», но по прежнему оставляет желать лучшего.
3. «Форматированный текст».
Степень соответствия оригиналу здесь сведена к минимуму - воспроизведение шрифтов и кеглей, примерного расположения материала на страницах оригинала, общего вида текста и таблиц.
Работать с этим вариантом заметно проще, чем с предыдущими, однако все еще затруднительно из-за большого количества стилей. Впрочем это достаточно просто лечится - можно быстро пройтись по тексту и наложить на него ваш собственный комплект стилей.
4. «Простой текст».
Хотя он называется «Простой текст», но здесь можно сохранять как сам текст, так и текст с картинками. Форматирование в этом варианте сведено к минимуму - обычные Word’овские абзацы от одного края страницы до другого, плюс воткнутые между ними картинки. Привычная по предыдущим вариантам куча стилей тоже не генерируется.
Но при желании даже здесь можно оставить исходную разбивку на строки и на страницы. Плюс сохранять начертания шрифта - обычный, курсив, полужирный.
Обычно для сохранения выбирается или «Форматированный текст», или «Простой текст» - в зависимости от того, что вы собираетесь делать дальше и как использовать распознанное.
Теперь об остальных настройках этого окна.
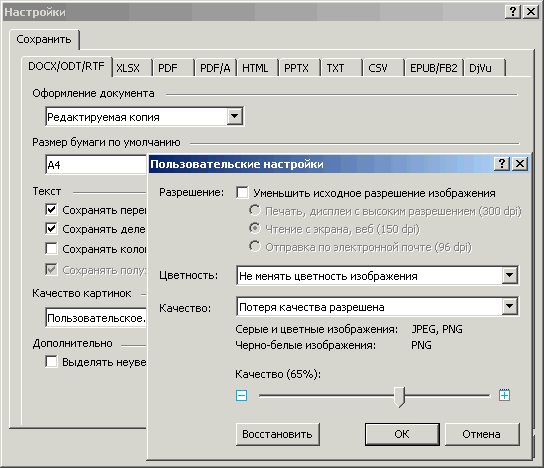
Рис. 28. Окно настройки качества изображения
Поскольку при уменьшении исходного разрешения и последующем сжатии возможны плохо предсказуемые искажения, то галочку «Уменьшать исходное разрешение изображения» лучше убрать.
Глубину цвета ставите по ситуации. Если изображения нужны, как есть, то выбираете «Не менять цветность изображения». Если достаточно просто общего вида, точное воспроизведение цветов не обязательно, то выбираете «Конвертировать цветные изображения в серые». Преобразование цветных и серых изображений в черно-белые лучше не выбирать, потому что бинаризация может давать много искажений (причем плохо предсказуемых). Пункт «Автоматически» тоже лучше не выбирать - не очень понятно какая логика работы там заложена и что вы при этом будете получать на выходе.

Рис. 29. Настройки сохранения в PDF
Режимов сохранения здесь тоже четыре: «Только текст и картинки», «Текст поверх изображения страницы», «Текст под изображением страницы», «Только изображение».
Теперь об остальных настройках этого окошка.
1. «Размер бумаги по умолчанию».
В PDF-выводе смысл этой настройки такой же, как и в предыдущем случае - формат листа, на котором будет печататься страница.
В предыдущем случае говорилось о правиле «если страница меньше, чем заданный формат, то вокруг текста будут пустые поля, если больше - часть текста будет обрезана». В PDF оно соблюдается еще более жестко, поскольку здесь исходная страница в любом варианте воспроизводится один к одному. Поэтому наиболее разумно ставить здесь «Использовать размер оригинала».
2. «Сохранять цвет фона и букв».
3. «Сохранять колонтитулы».
Смысл этих двух настроек такой же, как и в предыдущем случае.
4. «Создать оглавление».
Если в настройках распознавания была поставлена галочка «Определение структурных элементов → Оглавление», то распознанное таким образом оглавление книги может быть использовано для автоматического создания оглавления в PDF-файле.
5. «Разрешить теги PDF».
В PDF теги - это функциональный аналог Word-вских стилей, способ структурной разметки содержимого PDF-файла. С их помощью сохраняется информация о разбивке текста на главы, о заголовках, оглавлении, иллюстрациях, таблицах, примечаниях, гиперссылках, математических формулах и прочем подобном.
Если вам надо будет часто копировать из PDF куски текста, то галочку здесь стоит поставить. Тогда скопированный текст будет гораздо больше соответствовать тому, как он выглядит на странице PDF.
Также теги полезны если PDF приходится просматривать на экранах различных размеров - от десктопов до смартфонов. В таких случаях PDF-читалкам приходится переформатировывать содержимое страниц под текущий размер экрана и с теговой разметкой это проходит значительно более аккуратно, без заметных искажений первоначального вида.
6. «Использовать смешанное растровое содержимое (MRC)».
MRC (Mixed Raster Content) - это название технологии сжатия, способной давать заметно большие кратности сжатия, чем известные всем JPEG и JPEG 2000. Многие знакомы с ней по формату DjVu - он построен именно на базе MRC. Выбор «надо ставить галочку или нет» здесь неоднозначный и определяется исходя из вашего расклада дел.
Основной плюс - размер получаемого PDF. Может быть в несколько раз меньше PDF, полученного с теми же настройками сжатия, но без MRC.
Какие могут быть минусы:
MRC-сжатие так устроено, что при работе всегда дает плохо предсказуемое количество искажений. По причине того, что искажения здесь только частью зависят от настроек сжатия, а в изрядной мере от содержимого страницы. Текст, рисунки, графики, фотографии - при MRC-сжатии все они ведут себя заметно по разному и дают разное количество искажений.
Заметно большая ресурсоемкость при сжатии и просмотре таких PDF. Даже на сегодняшних компьютерах MRC-PDF может открываться и пролистываться не привычно-плавно, а скачками, когда очередная страница выводится на экран не вся сразу, а по частям.
7. «Сохранять картинки».
8. «Качество изображения».
Смысл этих настроек такой же, как и в предыдущем случае - надо или не надо при создании PDF сохранять изображения и с каким уровнем сжатия их сохранять. Рекомендации тоже аналогичные - убрать галочку из «Уменьшить исходное разрешение», цветность лучше не менять, движок «Качество» выставлять по аналогии со сжатием в JPEG 2000.
9. «Шрифты».
Если поставить «Использовать шрифты Windows», то для распознавания и последующего вывода будет использоваться тот набор шрифтов, который установлен у вас на компьютере. Если поставить «Использовать предопределенные шрифты», то только тот комплект шрифтов, который устанавливается при инсталляции FineReader.
Предпочтительнее выставлять первый вариант, поскольку при этом будет использоваться гораздо большее разнообразие шрифтов и программе будет легче подбирать соответствие шрифтам распознаваемых книг.
10. «Встраивать шрифты».
Если вам требуется, чтобы при просмотре PDF-файла на другом компьютере он был виден именно так, как вы его получили (именно в этих шрифтах), то надо поставить здесь галочку.
11. «Параметры защиты PDF».
Здесь можно выставить парольную защиту на просмотр PDF, печать, копирование из него текста и рисунков, редактирование.
Если у вас возникнут вопросы по работе FineReader, на которые вы не нашли ответа в тексте статьи, то их можно задать разработчиков программы.
Abbyy Finereader – программа для распознавания текста с изображениями. Источником картинок, как правило, является сканер или МФУ. Прямо из окна приложения можно произвести сканирование, после чего автоматически перевести изображение в текст. Кроме того, Файн Ридер умеет сконвертировать полученные со сканера изображения в формат PDF и FB2, что полезно при создании электронных книг и документации для последующей печати.
Как устранить проблему: ABBYY Finereader не видит сканер.
Для корректной работы Abbyy Finereader 14 (последняя версия) на компьютере должны выполняться следующие требования:

Если ваше оборудование не отвечает данным требованиям, программа может работать некорректно. Но и при соблюдении всех условий, Abbyy FineReader часто выдаёт разные ошибки сканирования, такие как:
В подавляющем большинстве случаев проблема связана с самим приложением и его настройками. Но иногда ошибки возникают после обновления системы либо после подключения нового оборудования. Рассмотрим наиболее распространённые рекомендации, что делать, если ABBYY FineReader не видит сканер и выдаёт сообщения об ошибках.
Есть ряд общих советов по исправлению некорректной работы:

В последней версии ABBYY FineReader также может носить название «Ошибка инициализации источника». Инициализация – это процесс подключения и распознавания системой оборудования. 
Если Файн Ридер не видит сканер при запуске диалогового окна сканирования и выдаёт такие ошибки, то должны помочь следующие действия:

ВНИМАНИЕ. Возможна и такая ситуация, что ни с каким из доступных драйверов выполнить сканирование не получилось. Тогда нажмите «Использовать интерфейс сканера».
Если и это не помогло, вам понадобится утилита TWAIN_32 Twacker. Её можно скачать с официального сайта ABBYY по ссылке ftp://ftp.abbyy.com/TechSupport/twack_32.zip.
После этого следуйте инструкции:

Если при запуске в Abbyy Finereader этого сделать опять не удалось, значит, проблема в работе программы. Отправьте запрос в техническую поддержку ABBYY. Если же и 32 Twacker не смог выполнить команду «Scan», то, вероятно, некорректно работает само устройство или его драйвер. Обратитесь в техподдержку производителя сканера.
Бывает, что при запуске сканирования приложение сообщает «Внутренняя программная ошибка, код 142». Она обычно связана с удалением или повреждением системных файлов программы. Для исправления и предотвращения повторных появлений выполните следующее:

Иногда Файнридер может не видеть сканер из-за ограничений в доступе. Запустите программу от имени администратора либо повысьте права текущего пользователя.
Таким образом решается проблема подключения программы Fine Reader к сканеру. Иногда причина в конфликте драйверов или несовместимости оборудования. А бывает, сбой сканирования возникает из-за внутренних программных ошибок. Если вы сталкивались с подобными проблемами в файнридере, оставляйте советы и способы решения в комментариях.